16. October 2022 · Lesezeit: 5 Min.
Automatische Sendungsvervollständigung bei Fr. Meyer’s Sohn

Über Fr. Meyer’s Sohn
Das Familienunternehmen hat sich auf den Transport von Massengütern wie Forst- und Agrarprodukte sowie Stahl spezialisiert. Es bietet Lösungen für den See-, Luft- und LKW-Transport sowie für den Schienen- und Binnenschiffsverkehr.
Jährlich werden über 850.000 TEU (Standardcontainer) befördert. In der Welt der Seefracht gehören sie zu den 10 größten Spediteuren. Bei der Beförderung von Papier und Zellstoff sind sie Marktführer.
Herausforderung
FMS organisiert den Transport von Containern, die in der ganzen Welt verschifft werden. Jede dieser Sendungen wird in einem internen System (SeaStep) erfasst.
Der Prozess beginnt damit, dass der Auftraggeber eine E-Mail an FMS schickt. Ein Sachbearbeiter überführt die Informationen aus der E-Mail in eine Sendungsmaske, das sind Ziel der Verschiffung, Art und Gewicht und Volumen der Ladung, sowie gewünschte Abfahrts- und Ankunftszeiten. Weitere Informationen zum Vorgang, wie geeignete Transportrouten, Start- und Zielhäfen usw. müssen ergänzt werden.
Diese Informationen müssen für jede Sendung jedes mal erneut eingegeben werden. Aufgrund von tausenden jährlichen Sendungen wird dieser Prozess ständig wiederholt. In der Automatisierung des Prozesses liegt daher ein großes Einsparungspotential.

Da die Transportrouten oft ähnlich sind, liegt die Vermutung nahe, dass die Informationen auf Basis weniger gegebener Daten, wie etwa Auftraggeber, Starthafen, Verschiffungsziel oder Art der Güter vorhersagbar sind. Diese Daten werden in der Regel in der Email-Korrespondenz zu einer Sendung erwähnt.
Wenn es also möglich wäre die Daten aus der Email-Korrespondenz auszulesen, und dann auf Basis dessen die weiteren Felder vorherzusagen, könnten die Sendungsmasken automatisch vorausgefüllt werden. Gegenstand unseres Projektes bei FMS war es, ein Verfahren zu entwickeln, dass in der Lage ist, fehlende Informationen automatisiert korrekt auszufüllen.
Lösung
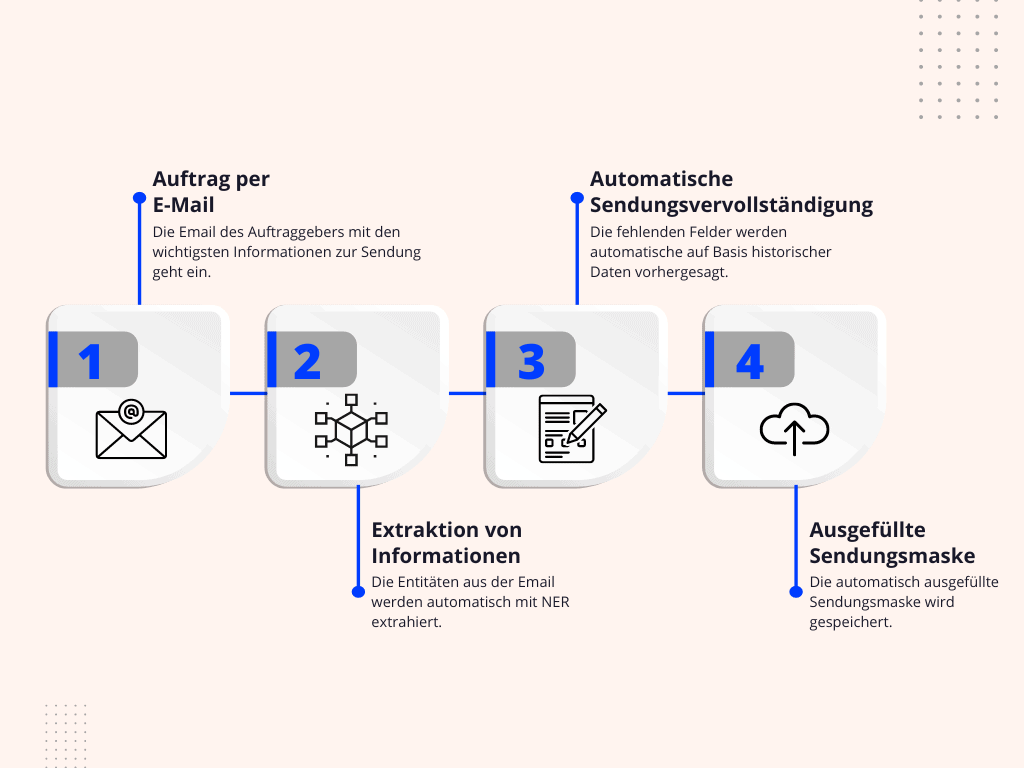
Um die Daten aus den Emails zu extrahieren, wird ein auf Named Entity Recognition basierendes Verfahren eingesetzt. So werden beispielsweise Häfen, Containermengen, Datumswerte und Namen von Ansprechpartnern erkannt. Alle noch fehlenden Informationen werden auf Basis von historischen Sendungsdaten vorhergesagt. In unserem Projekt mit FMS haben wir uns vor allem auf den zweiten Schritt konzentriert:
Automatische Sendungsvervollständigung auf Basis historischer Daten
Die Maske mit den aus den Emails vorausgefüllten Feldern enthält noch viele fehlende Felder, die ergänzt werden müssen. Um dieses Problem zu lösen, stehen hundert tausende historische Sendungsmasken zur Verfügung, die vollständig ausgefüllt sind. Die Aufgabe ist prädestiniert für, die fehlenden Felder mit maschinellen Lernverfahren vorherzusagen. Zum einen liegt ein großer Datensatz vor, der zum Anlernen von überwachten Lernverfahren verwendet werden kann und zum anderen finden sich offensichtliche Muster in den Daten. So korrelieren einige Felder stark miteinander, beispielsweise wählen Kunden oft ähnliche Routen mit ähnlichen Ladungen. Einige Werte ergeben sich auch zwangsläufig aus anderen (z.B. Ladehafen Hamburg → Verschifft über Deutschland). Diese “Business Rules” gilt es automatisch aus den Daten abzuleiten.
Mit klassischen maschinellen Lernverfahren wie Klassifikation oder Regression werden einzelne Werte vorhergesagt. Die Herausforderung besteht in unserem Fall darin, dass viele verschiedene Werte gleichzeitig vorhergesagt werden müssen. Für diese Klasse von Problemen werden sogenannte Imputationsverfahren angewandt.
Wir evaluierten zunächst einen State-of the-Art Imputations-Algorithmus (MissForest), der sich jedoch für diesen Anwendungsfall als zu ungenau und unperformant herausstellte. Daher entwickelten wir einen alternativen Ansatz, basierend auf dem K-Nearest-Neighbours Algorithmus und einem Rankingverfahren (BM25). Die Elasticsearch Suche schien uns hierfür das Mittel der Wahl zu sein.
Ergebnis
Durch eine Suche in den historischen Daten und anschließenden Aggregationen über die relevantesten Suchtreffern können die wahrscheinlichsten Werte für die fehlenden Stellen in den Sendungsmasken identifiziert werden. Wir konnten das Verfahren soweit optimieren, dass selbst, wenn beinahe alle Werte einer Sendung fehlen, diese mit einer Genauigkeit von über 90 % korrekt vorhergesagt werden. Zudem ist das System hochperformant, so dass eine Sendungsmaske in Echtzeit, auf Basis aller aktuell vorliegenden Daten, ausgefüllt wird.
Patrick Rosendahl
IT-Chef bei FMSWir hatten das Vergnügen mit exdatis an einem Data-Science-Projekt zu arbeiten und sie waren ein tolles Team. Sie verfügen über eine Fülle von Wissen und Erfahrung in diesem Bereich und waren in der Lage, unser Projekt vom Konzept bis zur Fertigstellung einwandfrei durchzuführen.