16. October 2022 · Lesezeit: 4 Min.
Kundensegmentierung mit KI für Biotech-Unternehmen

Über Lipotype
Von der einzelligen Bakterie bis zum hochkomplexen Menschen: Fette (Lipide) spielen eine wichtige Rolle in allen Lebewesen. Das sächsische Unternehmen Lipotype ist der weltweit führende Anbieter für die Analyse von Lipiden in der biomedizinischen Forschung. Die auf Massenspektrometrie basierende Lipotype Lipidomics Technologie ermöglicht eine schnelle und umfassende Identifikation von tausenden von Lipiden pro Probe.
Das internationale Team aus Molekularbiologen, Biostatistikern, Medizinern, Biochemikern, Massenspektrometrie-Spezialisten und Bioinformatik-Experten um den Firmengründer Prof. Dr. Kai Simons hat es sich zur Aufgabe gemacht, mithilfe eines detaillierten Zugangs zu Lipiddaten zum besseren Verständnis von Leben und Gesundheit beizutragen.
Herausforderung
Als Anbieter einer hoch-spezialisierten Technologie möchte Lipotype beim Produkt-Marketing die richtigen Zielgruppen ansprechen. Dafür möchten sie ihre Kunden besser kennenlernen, deren Interessen und Expertisen identifizieren und verstehen wie Kunden die Produkte von Lipotype einsetzen. Das Bilden von Kundensegmenten ist die Basis, um folgende Prozesse zu optimieren:
- Passgenaues Content- und Produkt-Marketing
- Vertriebsprozesse an Zielgruppen anpassen
- Rückschlüsse für die Produktentwicklung ziehen
- Neue Leads generieren, die den Zielgruppen entsprechen und diese zielgerichtet akquirieren
Lösung
Die Kunden und Interessenten von Lipotype sind in der Wissenschaft aktiv und veröffentlichen Publikationen im bio-medizinischen Bereich. Diese Publikationen stellen für uns einen Datenschatz dar, da dort bereits wertvolle Informationen über die Kunden von Lipotype stecken, wie z.B. in welchem Forschungsfeld sie tätig sind, mit wem sie kooperieren, an welchen Problemstellungen sie arbeiten und wie sie Lipidomics dafür einsetzen.
Die Grundidee besteht daher darin, Veröffentlichungen von Lipotype-Kunden zu finden und zu analysieren, ihre Expertisen und Interessen zu identifizieren, um dadurch das eigene Umfeld besser zu verstehen und Kundensegmente zu bilden.
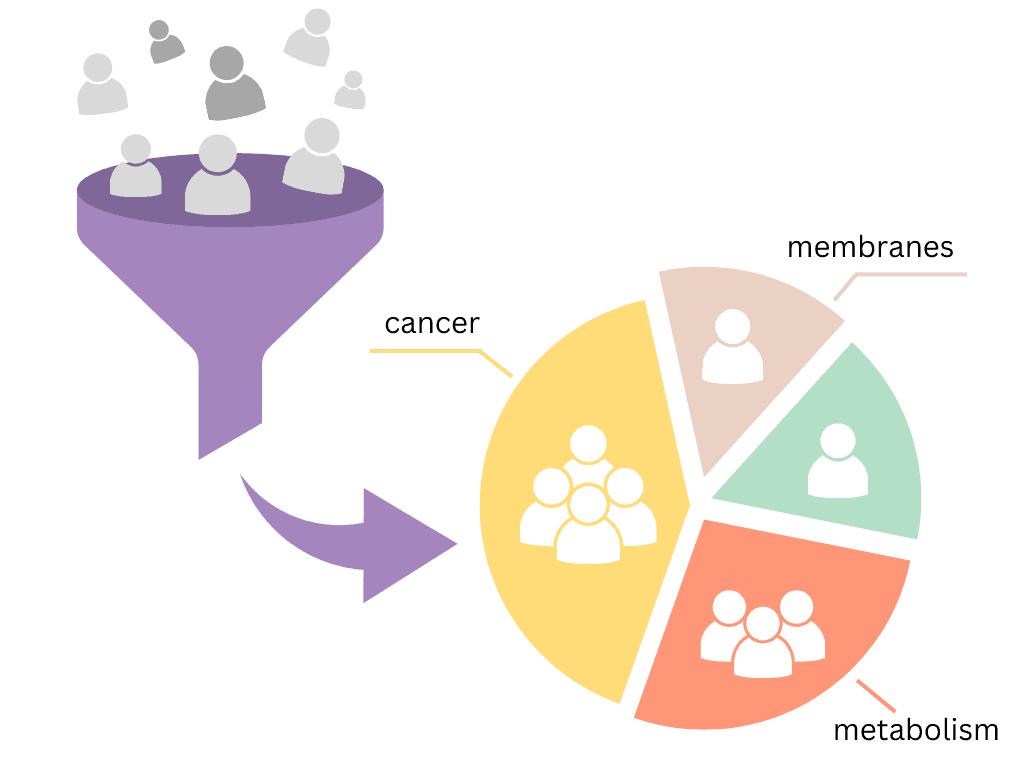
Um die Aufgabe manuell zu lösen, wäre es erforderlich die Publikationen aller Kunden zu lesen, thematisch zu erfassen und auszuwerten. Der zeitliche Aufwand hierfür wäre gigantisch. Mit den Mitteln der KI, genauer gesagt dem Unterbereich des Natural Language Processing, kann dieser Vorgang automatisiert werden.
Wir haben ein KI-Modell über Publikationen trainiert, das Beziehungen zwischen Autoren und Themen aufbaut. Das Modell analysiert die Publikationen und erfasst sie inhaltlich, es stellt thematische Gemeinsamkeiten und Unterschiede zwischen den Autoren her und kann so relevante Themen extrahieren.
Paper Scraping und Disambiguation von Autorennamen
Im ersten Schritt identifizieren wir die Publikationen der Autoren, die bereits Kunden oder Interessenten von Lipotype sind. Diese können aus öffentlichen Datenbanken bezogen werden, jedoch besteht die Schwierigkeit hier darin, dass es keine eindeutige Zordnung zwischen Namen und Publikationen gibt. So gibt es z.B. sehr viele Publikationen von John Smith, es ist jedoch unwahrscheinlich, dass es sich dabei um nur einen Autor handelt.
Wir haben daher ein Autor-Disambiguations-Modell entwickelt, welches auf Basis der verfügbaren Informationen (Name, Affiliation, Publikations-Inhalt,…) die Wahrscheinlichkeit für eine Zuordnung zwischen Namen und Autoren ermittelt.
Training des Autoren-Themen-Modells
Wir haben nun ein Pool von Publikationen der Lipotype Kunden und Interessenten zusammengestellt, die als Grundlage für das Modelltraining dienen.
Das Modell lernt Repräsentationen (sog. Embeddings) der Publikationen, in denen ihre inhaltlichen Eigenschaften kodiert sind. Es stellt somit Publikationen, Autoren und Themen in einem gemeinsamen Raum in Beziehung.
Kundensegmente definieren
Mit Hilfe dieser Repräsentationen können durch Clustering-Verfahren die Publikationen und Autoren in für Lipotype relevante Themenbereiche eingeteilt werden. Diese Cluster bilden die einzelnen Kundensegmente. Damit erhält Lipotype eine qualitative und quantitative Aussage darüber, welche Themen (spezielle Krebsarten, Behandlungsmethoden, etc.) bei welchen Kunden eine Rolle spielen und kann seine Strategien dementsprechend ausrichten.

Communications Officer bei LipotypeWenn man selbst kein Data Scientist ist, ist es schwierig komplexe Probleme im Marketing und Sales in „Data Science“-Sprache auszudrücken. Außer man arbeitet mit exdatis – dann werden die richtigen Fragen gestellt. Am Ende kannte ich mein Problem besser als zu Beginn, und gelöst wurde es auch!